.svg)

A Statsig audit is a structured review of your implementation covering SDK configuration, event tracking, API key setup, and experiment design. Most teams running Statsig have at least one misconfiguration that is silently producing unreliable data or experiment results, and they do not know it until someone digs in. This guide walks through exactly what a Statsig audit covers, the five areas most likely to have issues, and what correct setup looks like in each one.
Statsig is a powerful experimentation and feature flagging platform. But like any analytics tool, it only produces reliable results when it is set up correctly.
The problem is that most teams implement Statsig without in-house expertise on best practices. They get the basics working: events are firing, experiments are running, and assume the setup is correct. It usually is not. Misconfigurations in SDK setup, event naming, API key management, or experiment configuration create data quality issues that compound over time and produce results teams cannot trust.
An audit finds and fixes those issues before they cost you real decisions.
What Is a Statsig Audit?
A Statsig audit is a systematic review of your entire Statsig implementation. It covers how your SDKs are installed, how your events are named and structured, how your API keys are configured across environments, and how your experiments are designed and evaluated.
The goal is not just to find what is broken. It is to establish a foundation that scales, so every experiment you run from this point forward produces data you can actually act on.
The 5 Areas a Statsig Audit Covers
1. SDK Implementation and Environment Configuration
The most common starting point for Statsig issues is incorrect SDK setup. Teams often implement the wrong SDK for their use case, mix client-side and server-side SDKs incorrectly, or fail to configure separate environments for development, staging, and production.
Each environment needs its own API key. Running experiments in production with a development API key -- or failing to separate environments at all, means your experiment data is contaminated with internal traffic and test events. This is one of the most frequent issues found in Statsig audits and one of the easiest to fix once identified.
2. Event Naming Conventions and Property Structure
Event taxonomy is where most long-term data quality issues originate. Events named inconsistently like in snake_case, others in Title Case, others abbreviated differently across platforms make it impossible to run reliable analyses over time.
A Statsig audit reviews every event against a consistent naming convention, checks that key events have the right properties attached, and identifies events that are missing, duplicated, or structurally incorrect. The output is a clear remediation plan that brings your event taxonomy in line with best practices for long-term scalability.
If your events are also flowing into Amplitude or another analytics platform, fixing naming conventions in Statsig has downstream benefits across your entire analytics stack. This is also one of the reasons why most A/B tests fail: bad event tracking means bad experiment data regardless of how well the experiment is designed.
3. API Key Configuration
Statsig uses different API keys for different environments and different SDK types. Client-side keys, server-side keys, console API keys, each has a specific purpose and scope. Using the wrong key type in the wrong context is a silent source of data issues that is easy to miss if you do not know what to look for.
An audit checks that every environment has the correct key type, that keys are not being shared across environments, and that access controls are configured correctly. This is a quick fix that prevents a significant category of data reliability problems.
4. Experiment Configuration
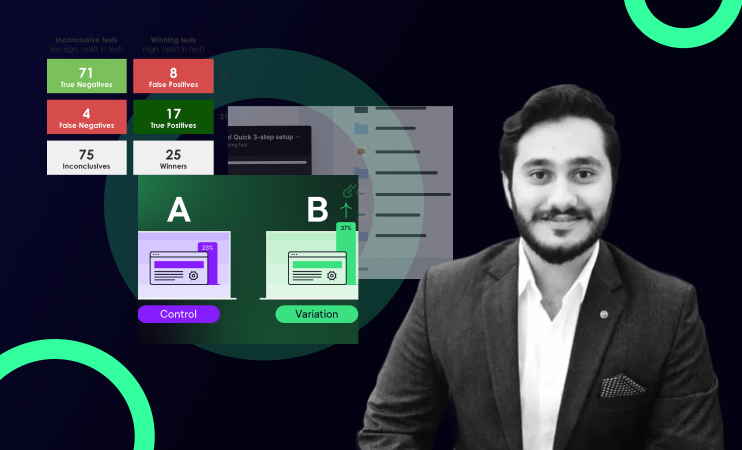
A well-designed experiment in Statsig requires correct setup across several dimensions: exposure rules that accurately define who is eligible, override settings for internal testing, targeting logic that reflects your actual user segments, and evaluation settings that match your statistical requirements.
Teams new to Statsig frequently misconfigure one or more of these. The result is experiments that expose the wrong users, produce contaminated results, or fail to reach statistical significance because the targeting was too narrow. The 8-step A/B testing framework covers what correct experiment design looks like -- the Statsig audit applies those principles specifically to your implementation.
5. Results Analysis Setup
The final area is how your team is evaluating experiment results. Statsig offers advanced analysis capabilities like sequential testing, CUPED variance reduction, guardrail metrics that most teams either do not know about or have not enabled correctly.
Sequential testing allows you to monitor results continuously without inflating your false positive rate. CUPED reduces variance in your results, making them more reliable with smaller sample sizes. Guardrail metrics catch cases where a variant improves the primary metric at the cost of something else. Not using these features does not mean your experiments are wrong, it means they are less reliable than they could be. The guide to avoiding false winners covers exactly why this matters in practice.
What Happens During a Statsig Audit Engagement
A structured Statsig audit engagement typically runs over two weeks and covers five steps.
An initial discovery call establishes your objectives like ,what you are trying to achieve with Statsig, where you are currently experiencing issues, and what a successful outcome looks like. A rapid audit of your existing setup follows, identifying incorrect configurations and producing clear recommendations for correction. A live demo session covers experiment setup, evaluation workflows, feature usage, and best practices specific to your stack. A detailed findings document is prepared outlining every issue identified, the recommended fix, and the priority order for implementation. A close-off call hands over the documentation and completes a final event audit.
The output is not just a list of problems. It is a remediation plan your team can implement independently -- and a foundation that scales as your experimentation program grows.
What Correct Statsig Setup Looks Like
After a Statsig audit, teams typically have the correct SDKs implemented for both event tracking and experimentation, API keys configured correctly across all environments, events designed with the right properties and naming conventions for long-term scalability, experiments configured with proper exposure rules and evaluation settings, and results analysis set up with sequential testing, CUPED, and guardrail metrics enabled.
That foundation is what makes every experiment you run from this point forward produce data you can trust and decisions you can defend.
Get the full Statsig 101 Getting Started Guide
The Statsig 101 guide covers the complete setup process in detail like SDK selection, environment configuration, event instrumentation, identity resolution, feature flags, and experiment setup, with worked examples and a setup checklist you can follow step by step.
👉Download the free Statsig 101 Getting Started Guide
.png)
See how we did this for Unravel
Unravel needed to set up Statsig quickly and correctly without the time to trial and error their way through the documentation. In two weeks, Adasight audited their setup, delivered a live best practices session, and handed over a complete findings document. Read the full case study.
👉Read the Unravel Statsig Audit case study
Want a free Statsig audit call?
Not sure whether your Statsig setup is producing reliable data? Book a free 30-minute call and we will review your setup and tell you exactly what needs fixing.
FAQ
What is a Statsig audit?
A Statsig audit is a structured review of your Statsig implementation covering SDK configuration, event naming and property structure, API key setup across environments, experiment design, and results analysis configuration. The goal is to identify misconfigurations that are silently producing unreliable data or experiment results and produce a clear remediation plan.
What are the most common Statsig setup mistakes?
The most common issues found in Statsig audits are incorrect SDK type for the use case, API keys not separated across development, staging, and production environments, inconsistent event naming conventions, experiment exposure rules that target the wrong users, and advanced analysis features like sequential testing and CUPED not being enabled.
How long does a Statsig audit take?
A structured Statsig audit engagement typically runs over two weeks. It includes a discovery call, a rapid audit of the existing setup, a live best practices demo, a detailed findings document, and a close-off call handing over the documentation and completing a final event audit.
Do I need a Statsig audit if my experiments are running?
Yes -- experiments running does not mean experiments are running correctly. The most common Statsig issues are silent: contaminated data from incorrect environment configuration, unreliable results from missing variance reduction settings, and skewed experiment populations from incorrect exposure rules. An audit finds these issues before they affect real decisions.
What is sequential testing in Statsig?
Sequential testing is an analysis method that allows you to monitor experiment results continuously without inflating your false positive rate. Unlike fixed-horizon testing where you can only evaluate results at a single predetermined point, sequential testing adjusts the significance threshold dynamically as data accumulates -- allowing earlier decisions when results are clearly significant.
What is CUPED in Statsig?
CUPED stands for Controlled-experiment Using Pre-Experiment Data. It is a variance reduction technique that uses historical user data to reduce noise in experiment results, making them more stable and reliable -- particularly useful when sample sizes are limited or when user behavior has high natural variance.